Social media engagement tools centralize cross-channel comments, mentions, and DMs within unified inboxes. Some platforms also include social listening and sentiment analysis capabilities to help social media teams summarize the audience's opinion on particular topics...
Redesign For multi-location brands
all your locations, one content flow
For multi-brand companies
content collaboration at scale
For agencies
impress your clients and take on more
“The team loved it from the start. Planable helps us overview the entire marketing efforts.“
As Planable’s SEO lead, I’ve spent years studying visibility: how brands show up, earn authority, and build trust. But visibility has changed. It’s now just as much about how AI sees you as how you rank.
It started with a simple question: does our social presence shape AI’s answers? The deeper we dug, the clearer it became: AI already learns from what we post, watch, and debate online. Every LinkedIn update, YouTube transcript, and Reddit thread feeds the models shaping what billions read next.
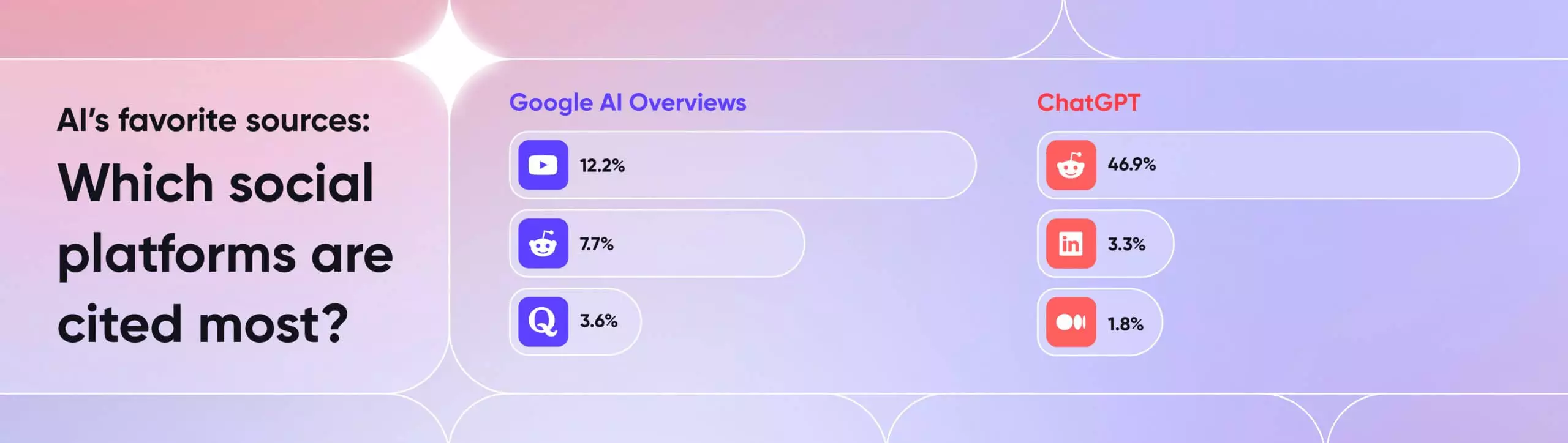
When someone asks an AI tool for advice (what agency to hire? which tool to try?) the answers come from the open web. And increasingly, from social. Data from SE Ranking shows that social and community platforms appear in over a third of Google’s AI generated responses. YouTube leads. Reddit and Quora follow. ChatGPT leans even more on Reddit, then LinkedIn and Medium.
This research isn’t built on guesses. It’s grounded in data from platform documentation, third-party studies, and large-scale usage data. The goal is to uncover how AI finds and interprets social content, which platforms matter most, and what that means for your visibility in the age of AI.
No hype or speculation, just what we know, and what it means for showing up in the systems shaping what the world learns next.
Get the PDF on your email
Quick AI terms glossary
AI crawler = a piece of software that systematically scans and indexes pages across the internet to collect data for AI models or search features. Crawlers help AI systems stay updated with new content and discover what’s publicly visible.
LLM (large language model) = the core technology behind tools like ChatGPT and Gemini. LLMs are trained on billions of text examples so they can generate human-like answers, summarize data, and understand context across topics.
AI training data = the massive collection of text, images, video transcripts, and other content that AI systems learn from. This determines how they understand tone, expertise, and authority.
AI retrieval = the process where an AI tool looks up information in real time from the live web or licensed databases to answer a question. Unlike training data, retrieval is dynamic and updates as the web changes.
R.A.G. (retrieval-augmented generation) = a hybrid method that combines AI’s internal knowledge with live web search results, helping systems provide more current and source-grounded answers.
Data licensing = formal agreements (like Reddit’s with Google or OpenAI) that give AI companies permission to use certain platforms’ content for training or retrieval.
Entity recognition = the way AI models understand and tag real-world things—like brand names, products, or people—so they can connect mentions across different contexts online.
Semantic understanding = the ability of AI to grasp meaning and relationships between words (for example, recognizing “buy a home” and “purchase a house” as the same intent). This is how AI reads beyond keywords.
Is AI learning from your social presence?
Yes, but there are some nuances. To understand how social media impacts AI presence, it helps to know a bit about how AI systems are built and learn.
Modern AI systems are trained on massive amounts of text, video transcripts, images, and other content gathered from across the web. These sources are used to train LLMs through a process called machine learning, where the AI identifies patterns in data to predict the most likely next word, phrase, or idea in a given context.
So AIs “learn” not by memorizing facts, but by generalizing from examples, many of which come from publicly available online spaces.
That means the internet’s conversations, arguments, and explanations all subtly shape how AI “thinks.” And few places generate more conversation than social media.
But access matters. For LLMs to read what’s being said on social, they need to be able to access that data. Some networks, like Reddit or Youtube, allow varying levels of access to their content. Others, such as Instagram or Facebook, are largely closed off. This availability shapes which platforms AI systems learn from and cite in their answers.
Recent SE Ranking research shows that 20% of AI Overview responses include at least one social media platform among their top 10 sources. In AI Mode, that number rises to 36%.
When it comes to which platforms dominate in Google’s AI answers, YouTube stands out as the clear leader, followed by Reddit and Quora. Together, these three make up the bulk of social-sourced content in AI results.
ChatGPT, on the other hand, relies more on Reddit, with LinkedIn and Medium following as the next most common platforms.
So next time an AI gives you an answer, there’s a good chance part of it came from someone’s YouTube video, Reddit comment, or LinkedIn post.
If I post more, does my brand rank more?
AI systemsreward credibility, not volume. Posting more can indirectly help if your content earns visibility, shares, and third-party mentions that signal trust.
A recent study, “Generative Engine Optimization: How to Dominate AI Search,” found that AI search systems favor earned (third-party, authoritative) mentions over brand-owned content or social media activity. As Sarah Evans noted in a recent LinkedIn post, LLMs now look for context: who’s mentioning you, where those mentions appear, and how often your name appears alongside certain topics or expertise.
That means mentions in trade publications, quotes in thought leadership pieces, or references in podcasts now act as trust signals. And this extends beyond backlinks. If your social posts inspire creators to discuss your brand, spark user-generated videos or in-depth reviews, or encourage your audience to tag you in expert roundups, these social signals reinforce credibility too.
So when posting more sparks credible mentions and conversations, consistency can help your brand surface more often in AI answers.
Which social platforms are part of AI training & retrieval data?
No AI provider has fully transparent public logs of exactly which platforms are used for training or retrieving data. But we can get a good picture from what’s been made public.
AI training vs AI retrieval
AI training refers to when AI learns from data. That information is built into the model’s memory and shapes how it understands, reasons, and responds.
AI retrieval refers to when the model looks up information in real time from the live web, APIs, or licensed databases to answer a query.
🚨 Most platforms restrict AI systems from directly accessing or training on their data. However, public content from any platform can still appear in AI outputs if it’s discoverable via search or shared elsewhere, for example:
public links are discoverable through search engines like Bing or Google index
the content is quoted, embedded, or summarized on another site such as Reddit, a blog, or a news outlet.
In these cases, AI systems are linking to or referencing the post, not training on or directly accessing the platform’s data.
Reddit
Access for ChatGPT (OpenAI): Open and licensed. Reddit has an official data-licensing partnership with OpenAI that allows ChatGPT to access Reddit’s real-time data through its Data API.
Access for Google AI:Open and licensed. Reddit also licensed its data to Google for AI training and search indexing in 2024.
Instagram
Access for ChatGPT (OpenAI) and Google AI: Closed for training, but partially open for indexing.
Meta does not provide Google (or any external AI provider) with training access to Instagram data. However, starting July 2025, Meta began allowing Google and Bing to index public Instagram content from professional accounts.
This means that while AI systems can’t directly train on Instagram data, they may now surface public Instagram posts (if those posts are indexed by Bing or Google).
Internal use: Meta trains its own AI systems (including LLaMA and Meta AI) on public Facebook and Instagram posts, but not on private messages or restricted content.
Facebook
Access for ChatGPT (OpenAI): Closed for training. Meta does not license its data to OpenAI. Scraping Facebook is prohibited.
Access for Google AI:Closed for training. Meta does not provide external access to Google either.
Internal use: Meta similarly trains its own AI models using public Facebook posts, but does not use private messages or restricted content.
X (Twitter)
Access for ChatGPT (OpenAI): Explicitly prohibited. X’s June 2025 Developer Agreement bans third-party AI systems (including OpenAI and Google) from training on or retrieving tweets.
Access for Google AI: Prohibited. No public licensing deal exists.
Access for ChatGPT (OpenAI): Restricted, creator opt-in only. YouTube forbids scraping or data reuse for AI training without permission. A “third-party AI training” toggle in YouTube Studio allows creators to opt in voluntarily.
Access for Google AI: Internal access only. Google uses YouTube content internally to improve Gemini and Search, subject to its own privacy and creator consent policies.
LinkedIn
Access for ChatGPT (OpenAI):Prohibited. LinkedIn’s terms forbid large-scale scraping or reuse by third-party AI systems, including ChatGPT.
Access for Google AI: Prohibited for training. No license for Gemini training; limited indexing for search only.
Internal use: LinkedIn uses its data internally to train recommendation and AI models within Microsoft’s ecosystem.
Do AI models access posts directly?
It depends on how the data is obtained. Direct access happens only when it’s explicitly allowed; otherwise, AI models rely on whatever’s publicly visible on the open web.
When companies have a license or internal access, they use the original posts, videos, or images directly. This, for example, applies to Reddit, X (for Grok), and YouTube for opted-in creators.
When access is restricted, AI models only learn about those platforms indirectly (through summaries, quoted text, or articles that mention or describe posts). For example, if a news site embeds a tweet or discusses a TikTok trend, that text might appear in general web data that models can crawl.
How frequently are AI models updated?
AI platforms do not publicly disclose the exact re-crawl intervals of their agents. But signs suggest it happens at least monthly and it’s becoming more frequent. Here’s how we know:
Cloudflare’s 2025 crawler telemetry reported a 305 % increase in GPTBot activity over one year. This means AI re-crawling has become more frequent overall.
Fastly’s Q2 2025 report noted that AI crawlers often show extended periods of low activity followed by sustained spikes “lasting days or even weeks.” In other words, AI agents operate in cycles rather than steady intervals.
The same report also described CCBot (used by Common Crawl and many AI models) running broad two-week crawls each month, with crawl volumes steadily increasing over time.
How does an AI chatbot decide which sources to cite?
AI chatbotsdraw on internal training data (a huge mix of publicly available text) to generate the response. For more up-to-date topics like news or emerging research, systems may hybridize: combining model output with a web search to ground the answer in recent sources.
Although the full process behind how AI systems choose their cited sources is not publicly known, research shows that certain factors play a role in those decisions.
Authority
There’s a lot of talk about how “authority” doesn’t really matter for LLMs anymore. But in reality, it still does (just in a new way). Instead of backlinks, AI seems to care more about brand mentions, which research shows are three times more strongly linked to appearing in AI answers.
Topical match & depth
AI systems prioritize content that directly and deeply addresses a specific topic. When evaluating sources, models like ChatGPT look for strong alignment with user intent and contextual relevance. This means that the more focused and comprehensive your content is (especially when it solves a clear problem), the more likely it is to be recognized and featured in AI responses. As Kevin Indig points out, hyper-targeted content isn’t just helpful for readers; it’s essential for visibility in AI search results.
Traditional SEO and content optimization tactics
For example,Google has made it clear that you don’t need any special tricks to show up in AI Overviews or AI Mode. The same SEO fundamentals still apply: creating useful, people-first content, maintaining crawl accessibility, using strong internal linking, and ensuring a positive user experience.
According to SE Ranking research, in about 92% of cases, AI Overviews include at least one link from a site that already ranks in the top 10 search results. In other words, if you’re already following best SEO practices and aiming for those top spots, you’re also putting yourself in the best position to appear in Google’s AI answers.
What’s interesting is that some tests hint that whatever shows up on Google often ends up being what ChatGPT can find, too. Chris Long even shared his experience of spotting ChatGPT using Google Maps links directly in the output.
AI systems also likely have internal scoring (e.g., confidence, reliability) that filters pages before citation.
Does platform authority influence visibility in AI answers?
No. While “authority” still matters for how AI systems weigh and rank content, it now competes with a more practical factor: data accessibility.
Let’s compare the authority perceptions of a couple of platforms:
LinkedIn: high perceived authority: real identities, professional credibility, and strong trust signals.
Reddit: community-driven: authority varies by subreddit and crowd moderation.
Despite those differences, in 2025, Reddit is the most cited in AI responses. For example, analytics from Profound show Reddit is the top domain cited by Google AI Overviews and Perplexity from mid-2024 to mid-2025, and the second most cited in ChatGPT, with a 400% growth.
Why?
Reddit’s visibility is tied to access, not reputation. It signed major data deals:
A content partnership with OpenAI, giving structured access to Reddit data
By contrast, LinkedIn restricts scraping and API access, which limits how AI systems can legally use its content. Medium has similar barriers: its paywall and lack of structured licensing make its data less accessible to AI training and retrieval systems. Because of this, both LinkedIn and Medium appear less often in AI answers. For example, SE Ranking shows these sources ranking 4th and 5th in Google’s AI answers. In comparison, they hold the 2nd and 3rd positions in ChatGPT’s answers (though both remain far behind the leader, Reddit).
Bottom line: Platform authority matters, but so do factors like content accessibility. Reddit, once seen as the least “professional,” now leads in AI visibility mostly because AIs can freely access and use its content.
How does your brand benefit when your content is linked by AIs?
It’s not quite the same as earning SEO backlinks, but AI citations still come with real benefits.
Links in AI answers don’t boost your site’s authority the way traditional backlinks do because AI outputs aren’t web pages that get indexed. They’re dynamically generated summaries referencing existing sources.
Still, there are indirect perks. If your content links keep appearing in AI responses, people might click through, bringing more traffic and visibility to your brand. According to SE Ranking, traffic from AI platforms has increased by more than seven times from 2024 to 2025. So being mentioned in AI answers is starting to matter a lot more.
What part of a post is most likely to be read or indexed?
A realistic hierarchy looks like this:
Main text body and titles → Transcripts (for multimedia) → Alt text and hashtags → Comments and other metadata.
The main text body, titles, and captions carry the most weight for both human readers and AI-based indexing systems because they contain the actual meaning or “story” of the post. They’re the parts that models like OpenAI’s embeddings and Google’s Search Indexers can best understand and rank.
When a post contains audio or video, the system needs textual equivalents (such as transcripts or subtitles) to make the content searchable. For example, YouTube automatically generates transcripts and captions so that its algorithms (and Google Search) can interpret the spoken words as text data. This allows AI to answer text-based queries even when the original content wasn’t written.
Elements like hashtags, alt text, and comments provide supporting metadata. Hashtags help with topical categorization; alt text helps accessibility and image search; and comments may influence engagement ranking but are not typically indexed for meaning in the same way as the main content.
Does AI understand visuals in posts?
Yes. As of 2025, multimodal AI models (e.g., OpenAI’s GPT and Google’s Gemini) can interpret image text, memes, screenshots, and visual layouts with high accuracy. Models parse embedded text through optical character recognition (OCR), identify objects and relationships between them, and combine visual details with surrounding text to infer meaning.
So, visual context is now an important part of how AI systems analyze and index content (even though cultural nuance and sarcasm still remain challenging for models to interpret consistently).
Are keywords and hashtags still relevant for AI comprehension?
Yes. Modern AI systems like ChatGPT increasingly rely onsemantic understanding to interpret meaning, context, relationships.
This means ChatGPT doesn’t just “see” the words; it understands what they mean in context. For example, phrases like “buy a home” and “purchase a house” are treated as similar because their semantic embeddings are close in meaning (even though the wording is different).
But this doesn’t make hashtags entirely obsolete. They may still carry value, especially in certain contexts.
Research in social media natural language understanding (NLU) shows that hashtags can give AI useful hints about a post’s topic, especially when the text is short or a bit messy (like on X/Twitter). It’s not that AI is directly dependent on hashtags, but they may help models pick up on context and group related ideas more accurately.
Do post formats affect how easily AI tools can “read” them?
Yes. The format of a post really changes how easy it is for AI tools to “read” or to pull out insights.
With a text-only post, AI can directly parse the text. It already comes in a format AI models expect, so sentiment, topic, and entity extraction are relatively straightforward.
When posts include images or carousels, AI tools typically must first apply OCR (optical character recognition) to convert visual text into a machine-readable form. But OCR has limits: it struggles with low resolution, stylized or curved fonts, handwriting, uneven lighting, or layered visuals. Modern OCR often performs well in clean, high-quality conditions, but in real social media posts, the error rate can rise.
For videos, there’s another step: automatic speech recognition (ASR) or transcript generation. But ASR systems are not perfect; they can mis-transcribe under poor audio quality, heavy accents, overlapping speech, or ambient noise.
Moreover, a single video may include both spoken words (needing ASR) and embedded text (needing OCR). So, AI tools usually use both methods together to understand what’s being said and shown before they can analyze the main topics, tone, emotion, and so on.
So in short: text posts are easiest for AI; carousels/images require OCR analysis; and videos rely on ASR reliability.
Can AI models identify posts from verified, trusted accounts?
There’s no proof that AI systems give special priority to posts just because an account is verified.
For instance, Google explains that its ranking systems (including AI features in search) are designed to highlight original content that adds unique value. So, having a verified badge or a real name doesn’t automatically make your content more likely to appear in AI answers.
However, when verified creators post unique and valuable content, their content may naturally rank higher in AI answers.
Similarly, ChatGPT does not prioritize information based on verification status or popularity of the source. Instead, when connected to the web, ChatGPT retrieves and summarizes content based on relevance, user intent, and recency of information (not whether a creator or website is verified).
Verified or trusted sources may appear more often only because they tend to produce higher-quality, credible content that matches user queries.
Do frequent social mentions boost my brand’s presence in AI answers?
Yes. Higher visibility across social and web media can raise the odds that an AI system will find and mention your CEO or brand. But how those mentions appear and where they’re found matters a lot.
First, LLMs like GPT-4, Claude, or Gemini learn about people and organizations through text exposure. When your brand or CEO’s name appears often across high-quality, context-rich sources, the model builds a stronger “entity representation.” Research on entity linking shows that rarely mentioned (or “long-tail”) names are much harder for models to recognize and describe accurately unless they appear repeatedly across sources.
Second, AI systems usually employ retrieval-augmented generation (RAG): before writing an answer, they first pull in relevant web pages or documents. If your CEO or brand is well represented in those retrievable sources, the AI is more likely to include you when forming an answer.
So, frequent, high-quality, well-linked public mentions do increase the chances of being found by AI. Still, many other factors (e.g., freshness, authority, context) impact whether an AI will actually cite you.
Does personal branding boost AI authority like it does in SEO?
There isn’t yet clear proof that personal branding directly affects “AI authority” like it does SEO. But it still matters, just in a different way.
What the research actually supports is that the level of brand or name recognition directly impacts how often LLMs mention you. This link is strongest in industries like banking & finance and CRM & marketing automation, where recognizable brands appear more frequently in AI outputs.
And to build this awareness, you need consistent personal branding that aligns your name with your expertise and area of specialization.
So, while personal branding doesn’t act as a ranking factor, it’s a key way to create the visibility that AI systems pick up on.
Are viral posts more likely to be picked up by AI?
Viral social posts may be more likely to be ingested, surfaced, or cited by AI systems, though mostly indirectly. The thing is, many training sets and retrieval systems lean on what’s already popular on the open web. For example, OpenAI’s GPT-2 was trained on “WebText,” a dataset built from webpages that were linked by Reddit posts with at least 3 upvotes. That makes a highly upvoted/linked item or the pages it points to far more likely to end up in training data.
For GPT-3, the authors report a training mix of 60% filtered Common Crawl, 22% WebText2, 16% Books, 3% Wikipedia. This means web pages that win attention and links (often downstream of social virality) dominate what models see at scale.
So, virality increases the chances your content is seen or cited by AI systems (yet not because models read “likes,” but because popularity drives links and authority).
And while newer models likely use more curated data, it’s safe to assume that post virality still increases the likelihood of inclusion in AI outputs.
Is engagement a credibility factor for AI, like backlinks in SEO?
There’s no solid evidence that AI answer engines treat social-media “engagement” (likes, comments, reposts) as a credibility signal the way classic SEO relies on link authority. The data that does exist points to other signals.
For AI Overviews, Google says success factors mirror traditional search guidance (helpful, accessible content). There’s no mention of social engagement as a ranking/credibility input for the AI format.
One research study defines a Generative Engine Optimization (GEO) score as a composite measure based on 16 pillars of page quality (including factors related to people-first content, provenance, freshness, and so on). The study found that pages with higher quality scores (i.e., those meeting at least 12 of these pillars) were significantly more likely to be cited by AI answer engines. Notably, none of the 16 pillars include any engagement-related metrics, such as likes, shares, or comments.
So, there’s no evidence to support the idea that AI systems use social engagement metrics as inputs for scoring web pages or citations. And if they did, it would probably raise important transparency concerns (since social engagement metrics are not objective indicators of quality or truthfulness).
Can AI spot fake engagement or bot activity?
At this point, there’s no public evidence that AI platforms can reliably detect fake social-media engagement or coordinated bot activity.
In fact, most AI platforms simply don’t have the same back-end visibility that social networks do. They can’t see IP patterns, device fingerprints, or internal engagement logs (the kinds of data you’d need to confidently identify fake accounts or manipulated interactions). Without that, detection is largely guesswork based on what’s visible on the open web.
Meta, by contrast, openly acknowledges that it uses AI and review teams to find and remove inauthentic behavior (including fake accounts and spammy engagement). It publishes regular transparency reports; still, Meta doesn’t reveal exactly how it flags suspicious patterns.
So, while AI companies may be exploring ways to downrank or ignore spammy-looking content, there’s no solid proof yet that systems like ChatGPT or Google’s AI can detect or filter fake engagement on their own.
Does LinkedIn’s professional tone give it more weight in AI?
Not exactly. SE Ranking data shows that LinkedIn is the 4th most popular social media source featured in Google’s AI Overviews (right after YouTube, Reddit, and Quora). In AI Mode answers, Medium moves up to 4th place, while LinkedIn ranks 5th.
This shows a clear preference within Google’s AI systems for conversational and community sources. However, professional and text-rich content (such as LinkedIn) does appear in their source mix often enough to suggest it benefits from credibility and expertise signals.
Interestingly, within ChatGPT, LinkedIn ranks as the second most cited social media source after Reddit. Yet, there remains a significant gap between the volume of references to Reddit and LinkedIn.
Are Reddit discussions prioritized because AI trains on them?
Reddit isn’t inherently prioritized in AI systems, yet its data often shows up prominently in AI answers. This happens mainly because Reddit content has been licensed to Google and OpenAI for AI training purposes. In other words, it’s not that Reddit is “boosted” in the ranking; it’s that the models have a lot of Reddit data to learn from.
Recent analyses support this:
SE Ranking reported Reddit as one of the top two most-referenced domains across AI summaries.
Search Engine Land found that Reddit was the most-cited single site in Google’s AI Overviews.
Do Reddit posts count more than comments?
There’s no evidence that AI systems assign higher weight to Reddit posts over comments.
LLMs typically process text in bulk, so both posts and comments are treated as text snippets during training. Since Reddit comments often contain valuable context, insights, and opinions, we can assume that they’re just as useful as the original post for language modeling.
Does the freshness of the post or comment matter?
This depends on how the AI is using the data:
For training data (what models are initially taught from), freshness is less important. Training datasets are compiled from large-scale historical snapshots (often months or even years old).
For real-time AI responses, freshness does play a role. For example, ChatGPT determines “which results to present, considering factors like user intent, relevance, and recency.”
Is X/Twitter still used post-2023 data restrictions?
Yes, but barely. And there’s a good reason.
X radically changed access. First, it tightened API and rate limits in 2023. Then, on June 4–5, 2025, X updated its Developer Agreement to ban third parties from using X content/API to train or fine-tune foundation/frontier models. That makes broad, legal ingestion hard for outside AI search engines. Internal use (e.g., xAI/Grok) is still allowed.
What that means in practice:
AI engines can still occasionally surface X content, but mostly indirectly (e.g., a news site quoting/embedding a post that is crawlable).
According to SE Ranking data, X/Twitter ranks in the top-10 of most cited social media domains in both Google’s AI Overviews and AI Mode. Still, it appears for just 0.07% to 0.24% of prompts. In other words, it’s still present, but its visibility has dropped to a minimal level.
Does Meta content influence AI, or is it hidden behind walls?
It influences AI a little, but direct visibility is low compared to open platforms.
Even though public Instagram content can now appear in search results (and, therefore, can be surfaced indirectly to AI systems that use indexed web data), this change has had little measurable effect on AI answers so far.
Based on SE Ranking research findings, Instagram does show up for about 1% of keywords. Facebook appears even less, showing up for no more than 0.39% ofprompts.
In another study on the top 100 most-cited domains in ChatGPT (U.S. and global), neitherInstagramnorFacebook appeared in the list. So, their count is extremely small relative to leaders like Reddit/Wikipedia.
As you can see, the impact of both platforms is minimal, with almost no difference between Instagram and Facebook.
How can we measure if social posts influence AI results?
Tracking how social content impacts AI visibility is still new, but a few tools are starting to make it possible. Some emerging platforms and APIs now monitor brand mentions, citations, and sentiment across major AI engines helping teams see when and how their content is referenced in AI responses.
One of the first dedicated tools for this is SE Visible. It connects the dots between what you publish and how AI tools respond. You can see where your brand appears in AI results (like ChatGPT or Google’s AI Mode), compare visibility before and after key campaigns, and spot when new social posts trigger mentions or sentiment shifts.
Get insights into AI answers, sentiment & competitor performance with SE Visible
SE Visible brings everything into a shared dashboard, so SEO, PR, and content teams can collaborate on the same AI visibility data and track brand impact across channels. It comes with a 10-day free trial, so be sure to check it out.
How long does it take for social content to show up in AI?
There’s usually a delay of a few hours to a few days between when new content is posted online and when it becomes visible in AI systems.
AI platforms generally don’t have direct access to social media data from sites like Instagram, X (Twitter), Facebook, or LinkedIn. For example, when ChatGPT uses its web-browsing or “web-enabled” mode, it retrieves information through the Bing search index, not directly from those platforms. This means that new content must first be indexed by Bing before it can appear in ChatGPT’s responses.
A recent user study shared on LinkedIn found that when Bing indexed new pages quickly through IndexNow (Microsoft’s instant indexing protocol), the pages appeared in ChatGPT within just a few hours. In other cases, it took a couple of days, depending on factors like crawl frequency, site authority, and how well the content is linked internally.
Similarly, for content to appear in Google’s AI Overviews or AI Mode, it first has to be indexed in Google Search. That process can take anywhere from several hours to a few weeks, depending on the same kinds of factors.
Finally, with licensed data partnerships (such as OpenAI’s deal with Reddit), some AI systems can now access certain platforms’ content in real time or near real time. This reduces (or even eliminates) the delay for those specific data sources.
Relentless advocate and practitioner of putting users before Google algorithms since 2016. Geeks out over everything tech SEO. Dabbles in photography and is a natural-born reader.